NVIDIA CUDA – GPGPU la cel mai inalt nivel

![]()
Mult timp am auzit expertii IT vorbind de puterea imensa a unui procesor grafic modern (GPU) comparativ cu cea a unui procesor (CPU) dar pana acum nu am putut realiza o comparatie directa intre cele doua unitati de calcul. Odata cu introducerea de catre NVIDIA a tehnologiei CUDA putem folosi GPU-ul pentru diferite activitati care necesita putere de calcul foarte mare. Conceptul de GPGPU (General-Purpose computation on GPUs) nu este nou, el avand cateva implementari destul de primitive inca de acum multi ani. La acel timp neexistand procesoarele complet programabile din prezent, dezvoltatorii erau limitati la folosirea numai a unor functii cum ar fi rasterizarea si Z-Buffering. O data cu aparitia shaderelor au fost dezvoltate aplicatii de accelerare a matricilor. Cel mai cunoscut compilator din acele timpuri este BrookGPU care a fost creat pentru calculul pe GPU fiind bazat pe limbajul de programare Brook.
CUDA (Compute Unified Device Architecture) este un compilator si un set de dezvoltare al programelor menite sa ruleze pe GPU-urile NVIDIA. Limbajul de programare folosit este limbajul C cu un set de extensii aditional, deci preia atat avantajele cat si dezavantajele acestuia. Principalul avantaj si cel mai important este simplitatea si raspandirea acestui limbaj printre programatori, fapt ce usureaza foarte mult dezvoltarea de noi aplicatii CUDA. Elaborarea unui nou limbaj ar fi fost pe cat de costisitoare, pe atat de greu de implementat.
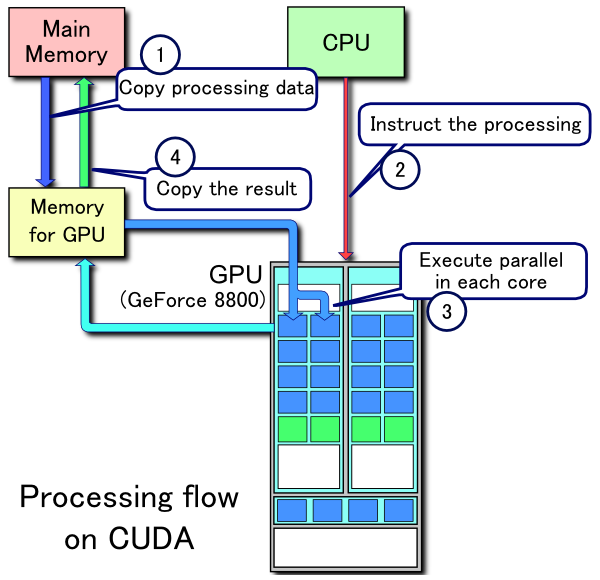
Proiectul CUDA a fost anuntat impreuna cu nucleul G80 in Noiembrie 2006, iar versiunea publica beta al CUDA SDK a fost lansata in Februarie 2007. CUDA 1.1 a introdus functii CUDA driverelor NVIDIA iar orice program CUDA necesita o placa video din seria GeForce 8 sau mai noua si un driver ForceWare 169.XX sau mai nou. Cea mai recenta versiune, CUDA 2.0, a fost lansata o data cu nucleul GT200 (GeForce GTX 260 / GeForce GTX 280) si adauga suportul pentru dubla precizie in virgula mobila (facilitate hardware prezenta in nucleul GT200), suport pentru texturile 3D, transferuri de date optimizate si multe altele.
Dar de ce pe GPU?
In primul rand trebuie sa intelegem diferentele arhitecturale intre un CPU si un GPU in ceea ce priveste modalitatea de executie a instructiunilor si implicit a comenzilor. Procesoarele actuale au in componenta pana la 4 nuclee iar dezvoltarea procesoarelor cu mai multe nuclee nu va fi prea simpla din cauza dificultatilor tehnice dar si a consumului extrem de ridicat. Fiecare nucleu poate functiona independent si poate executa diferite instructiuni pentru diferite procese.
Instructiunile multimedia, introduse incepand cu anul 1999 in procesoare, SSE (Streaming SIMD Extension) sunt instructiuni vectoriale pentru 4 componente (precizie simpla in virgula mobila) si pentru 2 componente (dubla precizie in virgula mobila). Aceste instructiuni au fost introduse in CPU din cauza cresterilor tot mai mari, la acea vreme, a necesitatilor aplicatiilor grafice. Acesta este motivul pentru care este mai bine sa folosim GPU-ul pentru anumite sarcini pentru ca acestea au fost gandite din start pentru GPU.
Spre deosebire de CPU care functioneaza dupa principiul MIMD (Multiple Instructions / Multiple Data), GPU-urile sunt alcatuite din mult mai multe nuclee (240 pentru varful de gama GeForce GTX 280) care functioneaza dupa principiul SIMD (Single Instruction / Multiple Data). Aceste nuclee executa aceleasi instructiuni simultan, acest algoritm fiind utilizat pentru algoritmii grafici si pentru multe activitati stiintifice. Aceasta abordare necesita programare specifica dar permite marirea numarului unitatilor de executie prin simplificarea functionarii lor.
Ideea de baza este aceea ca nucleele dintr-un procesor sunt gandite sa execute un singur fir de instructiuni secventiale cu viteza maxima pe cand GPU-ul este gandit pentru executia rapida a mai multe fire paralele de instructiuni. Iar pe langa aceasta paralelizare, GPU-urile moderne pot axecula chiar si mai multe instructiuni intr-un ciclu.
Un alt aspect care trebuie luat in considerare este accesul la memorie. Nu toate CPU-urile dispun de controller de memorie integrat pe cand toate GPU-urile dispun de mai multe controllere integrate (8 controllere de 64 biti echipeaza varful de gama NVIDIA GeForce GTX 280). In plus placile video folosesc memorie mai rapida drept urmare GPU-urile beneficiaza de mai multa latime de banda care poate oferi un avantaj semnificativ in calculele paralele cu fluxuri mari de date.
Diferente intre CPU si GPU sunt si in operatiile care necesita mai multe fire de executie. Astfel CPU-ul poate excuta 1-2 fire de executie pe fiecare nucleu in timp ce GPU-ul poate sustine pana la 1024 fire de executie pe fiecare nucleu. Trecerea de la un fir de executie la celalalt este penalizata in sute de ciclii in cazul CPU-ului pe cand GPU-ul poate executa mai multe treceri in fiecare ciclu.
Pe scurt, spre deosebire de procesoarele moderne, GPU-urile sunt gandite pentru calcule paralele cu multe operatii aritmetice. Urmatoarea diagrama arata impartirea in unitati a CPU si GPU:
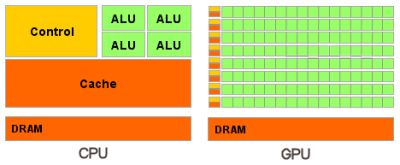
Tinand cont de structura unui GPU putem concluziona ca foarte multe aplicatii de modelare moleculara sunt numai bune de rulat pe GPU din cauza faptului ca acestea necesita putere mare de calcul si sunt potrivite pentru calculul paralel. Stiind acest fapt nu este de mirare ca unul din primele domenii in care a fost folosit GPU-ul s-a ocupat tocmai de studiul infasurararii proteinelor, proiectul Folding@Home al Universitatii Stanford.
Teoria e buna dar cum stam cu practica?
Desi a fost lansata de ceva timp, aplicatiile care pot profita la maxim de NVIDIA CUDA au aparut de-abia in a doua jumatate a acestui an. In randurile ce urmeaza vom analiza sporul adus de procesarea pe GPU in comparatie cu calculul folosind procesorul sistemului in 4 aplicatii optimizate pentru CUDA.
- CPU: Intel Core 2 Duo E8600 @ 4000MHz
- COOLING: CoolerMaster Hyper Z600
- MB: GIGABYTE X48T-DQ6
- RAM: 2×1GB Kingston PC3-14400 @ 1600MHz 7-7-7-20 1T
- VGA: Zotac GTX 260 AMP² (Core 216) @ 650/2100
- HDD: Seagate 7200.10 250GB 16MB
- PSU: CoolerMaster Real Power Pro 1250W
- OS: Windows Vista 32bit Ultimate SP1
- DRIVERS: NVIDIA ForceWare 180.43
Folding@Home
Proteinele se reunesc printr-un proces pe care biologii il numesc “infasurare”. Scopul proiectului Folding@home este intelegerea infasurarii proteinelor, infasurarii gresite şi bolilor cauzate de aceste erori. Folding@home simulează plierea proteinelor pentru a intelege modalitatea in care se pot infasura proteinele atat de rapid si sigur, pentru ca apoi sa se poata studia ce se întampla atunci cand procedura este gresită. Se crede ca boala Alzheimer, fibroza cistica, BSE (boala vacii nebune), o formă ereditară a emfizemului pulmonar si multe forme de cancer sunt rezultatul infasurarii gresite. Aplicatia Folding@Home este un program gratuit care ruleaza în background, permitandu-le utilizatorilor obisnuiti să sustină in mod real procesul de descoperire a unui tratament pentru aceste boli.
Pe pagina oficiala a proiectului sunt disponibile versiuni atat pentru CPU cat si pentru GPU ale clientului de folding. Pentru monitorizarea puterii de calcul am folosit programul FAHMon care monitorizeaza activitatea clientilor de folding raportand cate puncte realizeaza pe zi fiecare client (PPD). Pentru CPU am folosit 2 instante ale clientului pentru a incarca la maxim ambele nuclee.
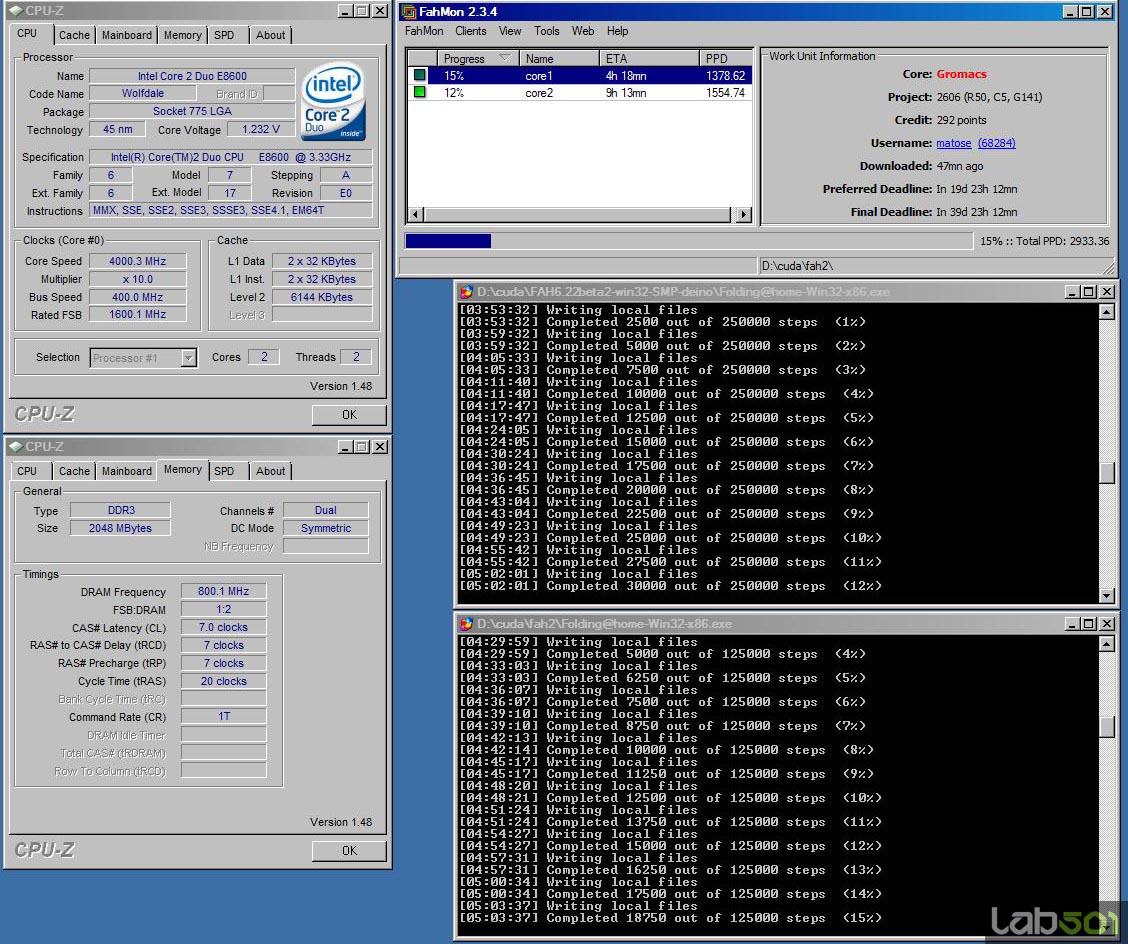

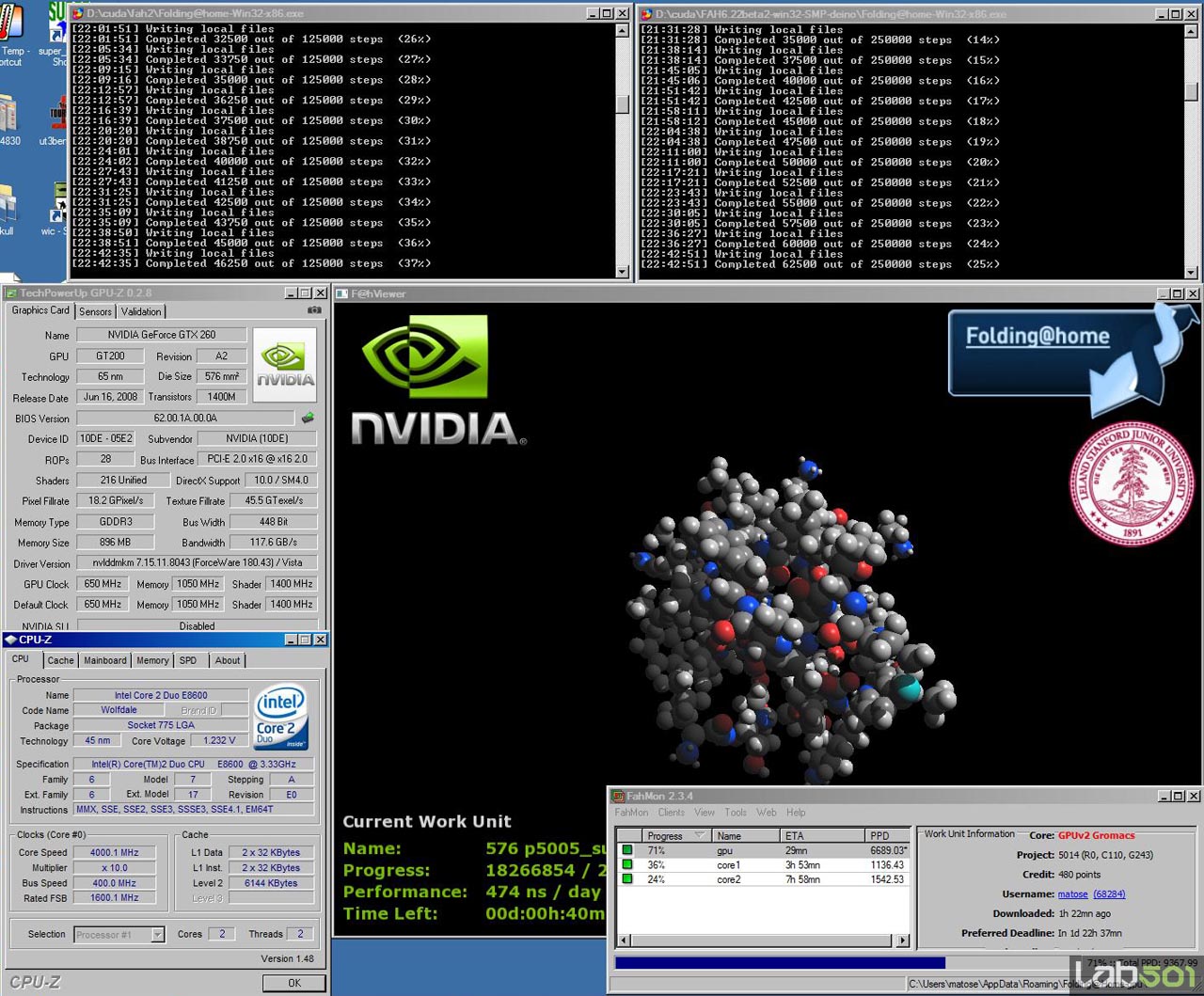
Se observa ca sarcina pe GPU este calculata de 2.24x mai repede decat pe procesorul nostru dual-core ruland la 4000MHz. Impresionant as putea spune, mai ales ca procesorul este mentinut la maxim 15% incarcare atunci cand ruleaza numai clientul pentru GPU, astfel sistemul fiind disponibil pentru alte activitati (inafara de activitati grafice bineinteles). In final am pornit toti cei 3 clienti si am monitorizat productia care a atins astfel 9376 PPD, o cifra neverosimila acum ceva timp.
TMPGEnc 4.6.2.266 Express
Cunoscutul software de conversie al materialului video al celor de la Pegasys incorporeaza in ultima sa versiune posibilitatea de a folosi tehnologia CUDA 2.0 pentru conversia materialului video dar si pentru filtrare.

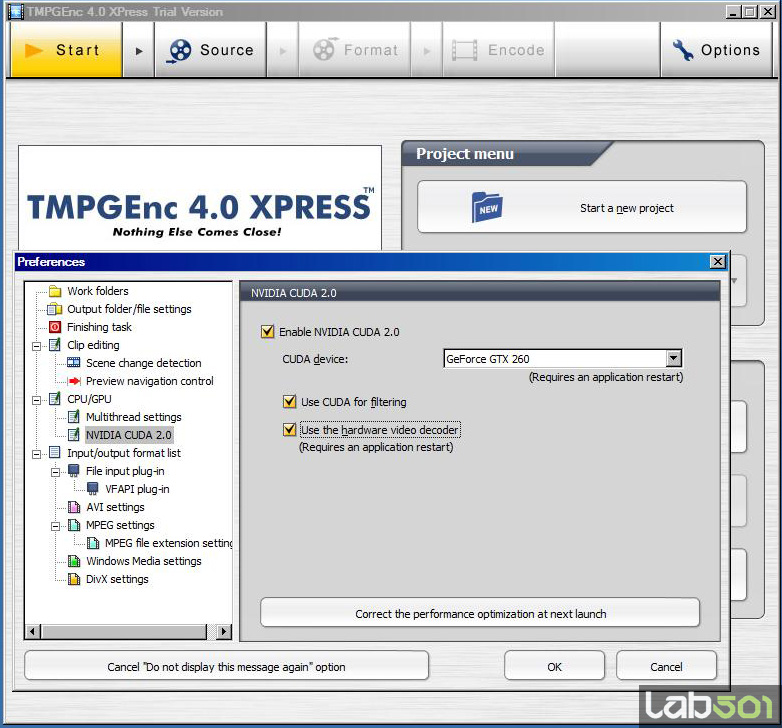
Pentru acest test am folosit primele 30 minute din DVD-ul Shoot Em Up aplicand urmatoarele filtre: Deinterlace, Video Noise Reduction (setare: Normal) si Color Correction (corectii de contrast si luminozitate). Codarea a fost realizata folosind codec-ul DivX, preset-ul Home Theater, Medium Quality.

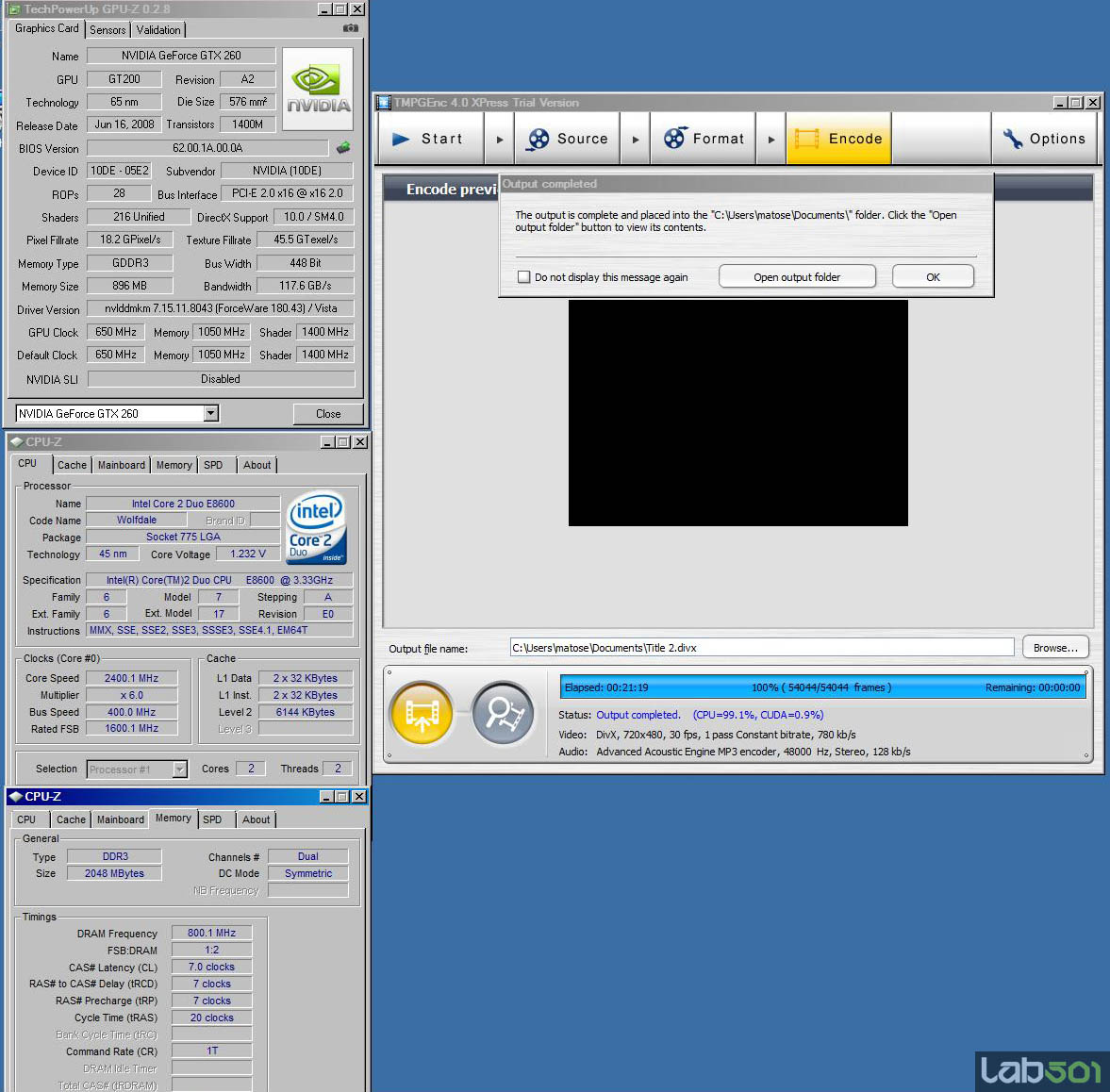
Codarea folosind CPU + CUDA a fost terminata cu 43 % mai repede decat cea exclusiv pe CPU. Bineinteles, la aplicarea mai multor efecte cat si cu cresterea complexitatii de codare acest procent va creste si mai multe in favoarea combo-ului CPU+CUDA.
Badaboom 1.0 Final
Elaborat de Elemental Technologies, Badaboom este un convertor multimedia bazat pe tehnologia NVIDIA CUDA pentru a accelera conversia materialui video folosind un GPU capabil CUDA. Pentru acest lucru este folosit RapiHD Video Platform al celor de la ETI (implementat mai nou si un Adobe Premiere Pro CS4) pentru a coda material video folosind GPU-ul in format H.264 pentru a fi folosit in dispozitive multimedia portabile: IPod, Zune sau IPhone. Pentru testul nostru am folosit Badaboom pentru a coda primele 10 capitole din DVD-ul cu filmul Shoot Em Up in format specific Apple IPod dar si in format specific Sony PSP. Tinand cont de faptul ca Badaboom nu poate realiza codarea folosind in exclusivitate procesorul pentru comparatie am folosit programul Handbrake, care are o interfata asemanatoare Badaboom si beneficiaza de optimizari pentru codare multithreaded. Am realizat cu Handbrake aceleasi setari cronometrand timpul necesar pana la finalizarea sarcinii.
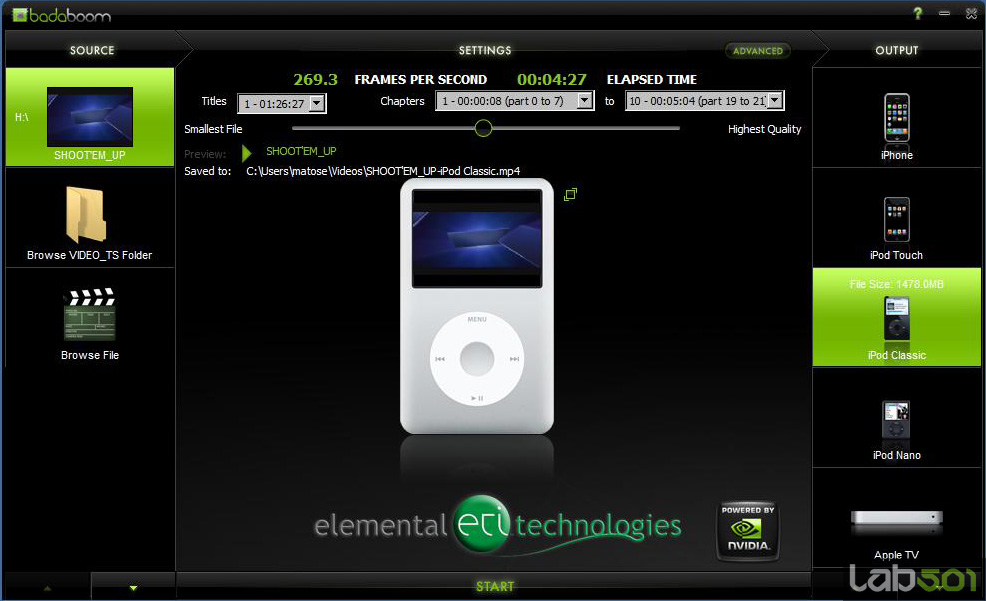

Se observa ca sarcina a fost finalizata de aproape 2 ori mai repede pe GPU, decat pe CPU in acest caz. Trebuie tinut cont ca folosind Apple iTunes sau un program asemanator timpul de codare era semnificativ mai mare pentru ca aceste programe nu ar fi beneficiat se suportul multithreaded al Handbrake.
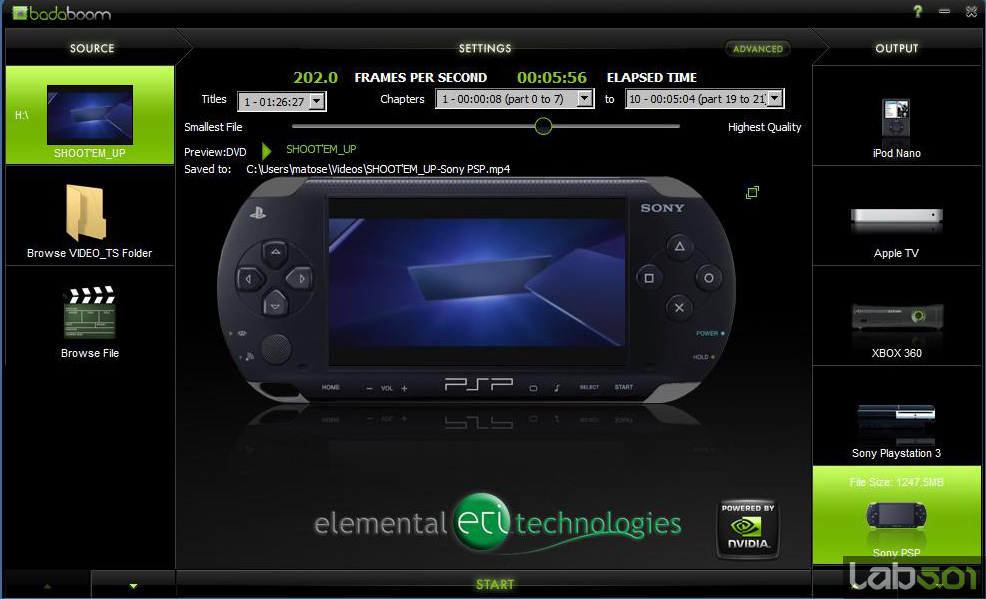
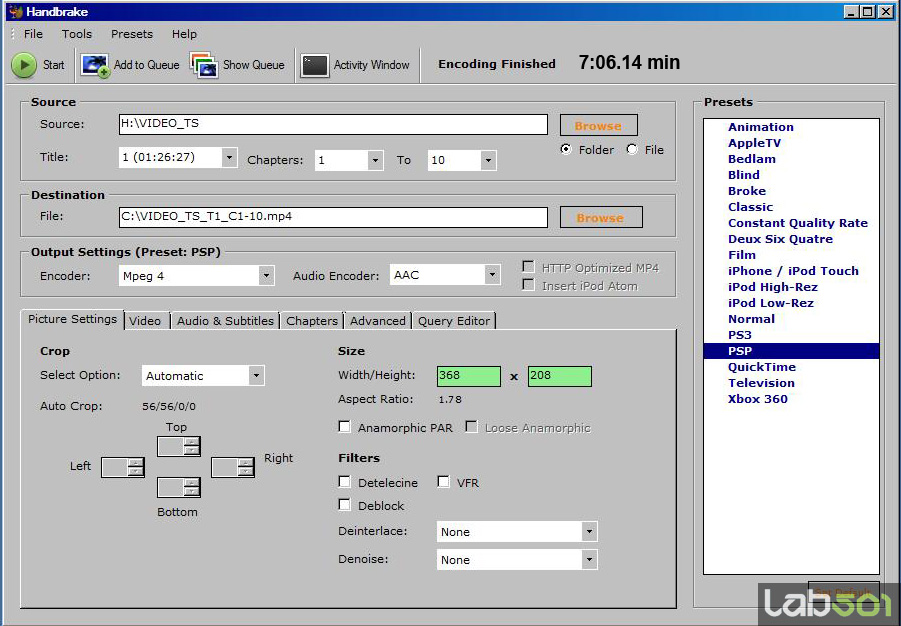
In acest caz imbunatatirea a fost de doar 20% in favoarea codarii pe GPU, semn ca diferentele sunt accentuate cu cat sarcina este mai complexa. Trebuie tinand cont si de efectuarea testelor cu programe diferite ceea ce ar putea induce diferente de calcularea a codarii.
FutureMark 3D Mark Vantage 1.0.1
Odata cu achizitionarea companiei Ageia de catre NVIDIA, aceasta a preluat si dezvoltat mai departe motorul de prelucrare a fizicii, PhysX. Implementarea acestuia in produsele NVIDIA se realizeaza prin CUDA, iar prima aplicatie aparuta capabila sa exploateze aceasta facilitate a fost 3D Mark Vantage, primul benchmark exclusiv DirectX 10. In testul de fizica: cand aplicatia detecteaza capabilitati de fizica vom avea un numar de porti egal cu numărul de nuclee de procesoare -1, plus inca 4 porti lasate in sarcina acceleratorului PhysX (GPU). Atunci cand capabilitatile de fizica nu sunt detectate numarul de porti este egal cu numarul de nuclee ale procesorului.
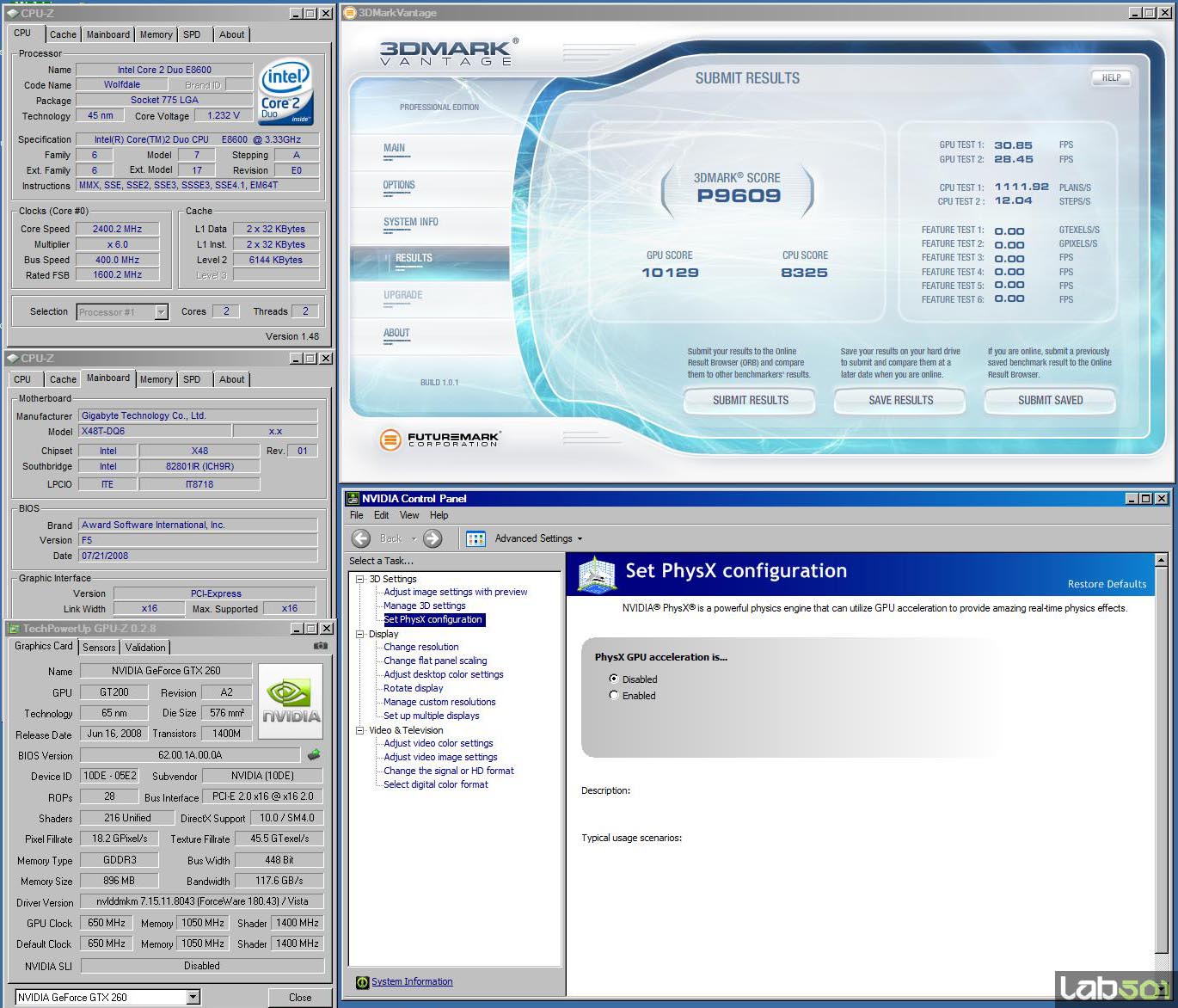
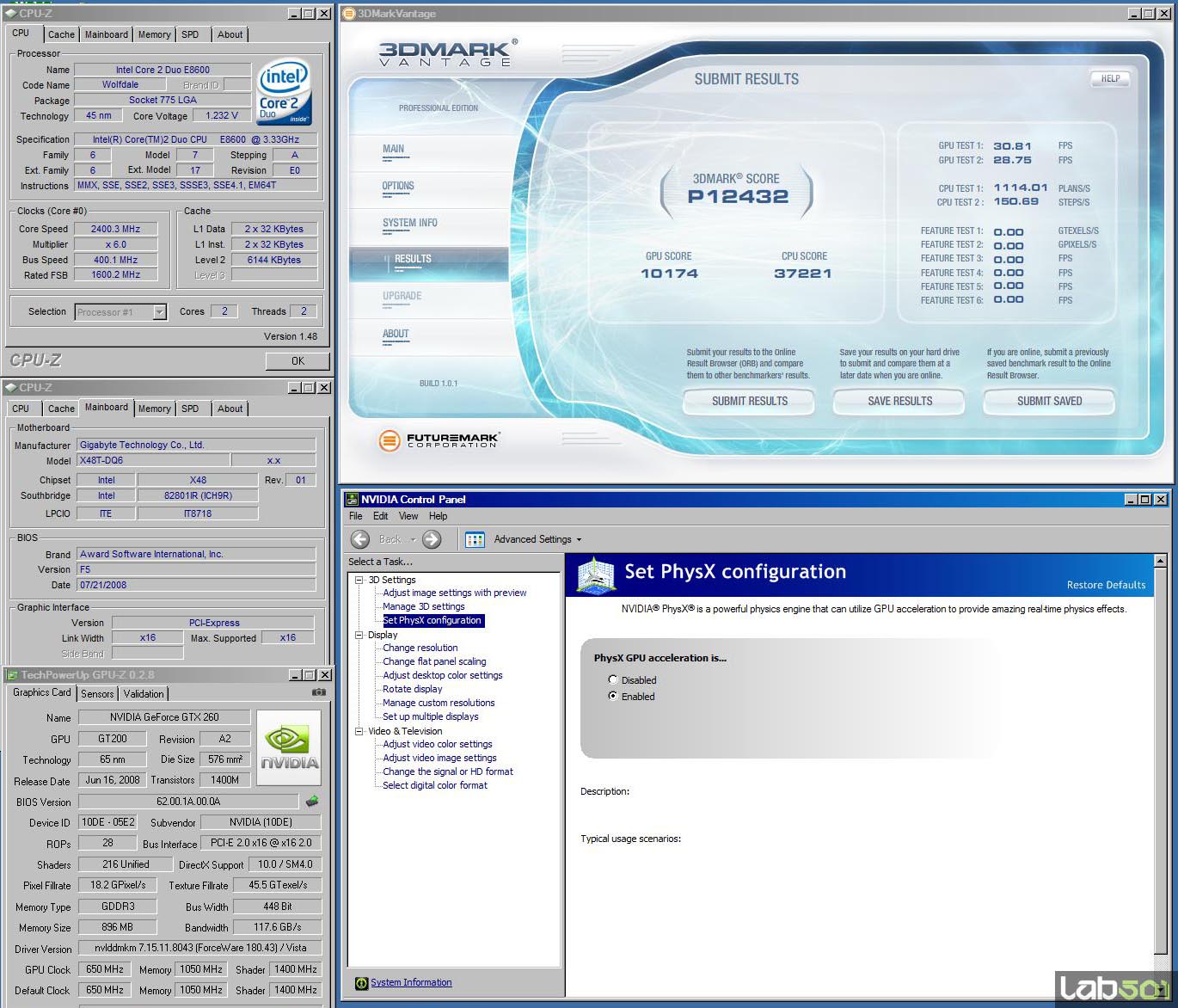
Se observa o crestere a scorului Physics (CPU) cu 450%, ceea ce se reflecta intr-o crestere cu 30%. Trebuie amintit ca in cazul jocurilor folosind efectele de fizica randate pe GPU performanta va suferi o scadere, dar fizica jocului va fi redata semnificativ mai natural.
Concluzii
Genul de aplicatii pe care le-am vazut astazi (si anume cele care folosesc tehnologia CUDA) sunt inca putine. Dar numarul lor creste in fiecare zi, si in fiecare zi procesoare high-end sunt inlocuite de placi video ce costa mai putin si sunt mai rapide. Deschiderea imensei puteri de procesare a acceleratoarelor grafice pentru orice fel de aplicatie e un pas tehnologic foarte important, aducand un salt de viteza mai mare decat orice noua generatie de procesoare a putut-o aduce vreodata in trecut. Implicatiile pot fi importante, daca ne gandim ca deja exista software destinat previziunilor financiare sau simularilor meteorologice ce ruleaza pe placi video Nvidia cu o eficienta nemaiintalnita pana acum.
Articolul poate fi discutat si pe CrazyPC.ro >>

Comentarii









Am ajuns aici cautand o placa video CUDA pentru minerit bitcoin, litecoin sau alte monede virtuale… Acum am inteles mai bine cum sta treaba
Pingback: 2.800 lei gaming - Page 4 - My Garage