NVIDIA Geforce RTX 2080 & 2080 Ti – Part II – Arhitectura Turing

Noutati
Turing reprezinta un mare pas in fata, atat din punct de vedere al arhitecturii interne, cat si a tehnologiei de fabricatie folosite (12nm FinFET). Mai mult decat atat, Geforce RTX va fi prima placa video consumer care va include nuclee Tensor, intalnite prima data pe Titan V, bazat pe nucleul GV100 si arhitectura Volta. SM-ul lui Turing mai beneficiaza de executie concomitenta a operatiunilor in virgula mobila si integer, cache L1 imbunatatit, nuclee Tensor precum si nuclee dedicate RT (ray tracing).
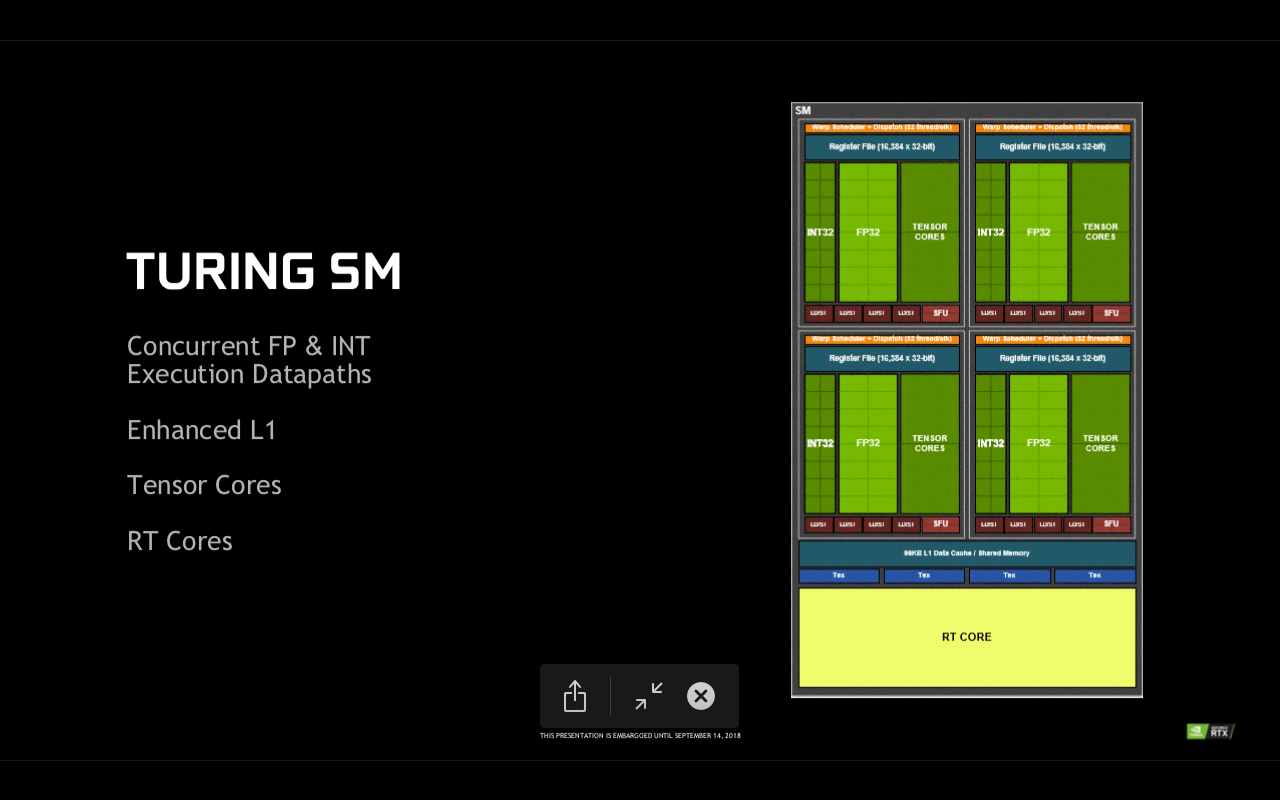
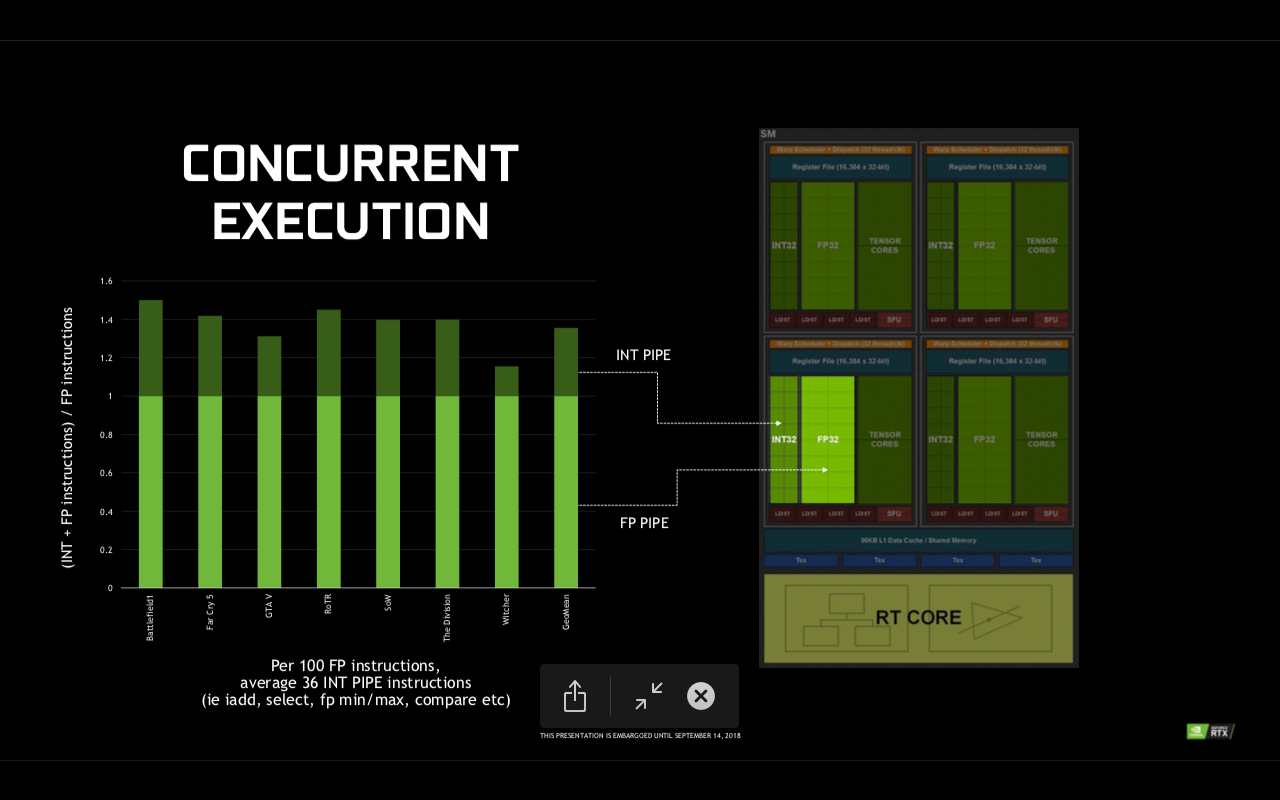
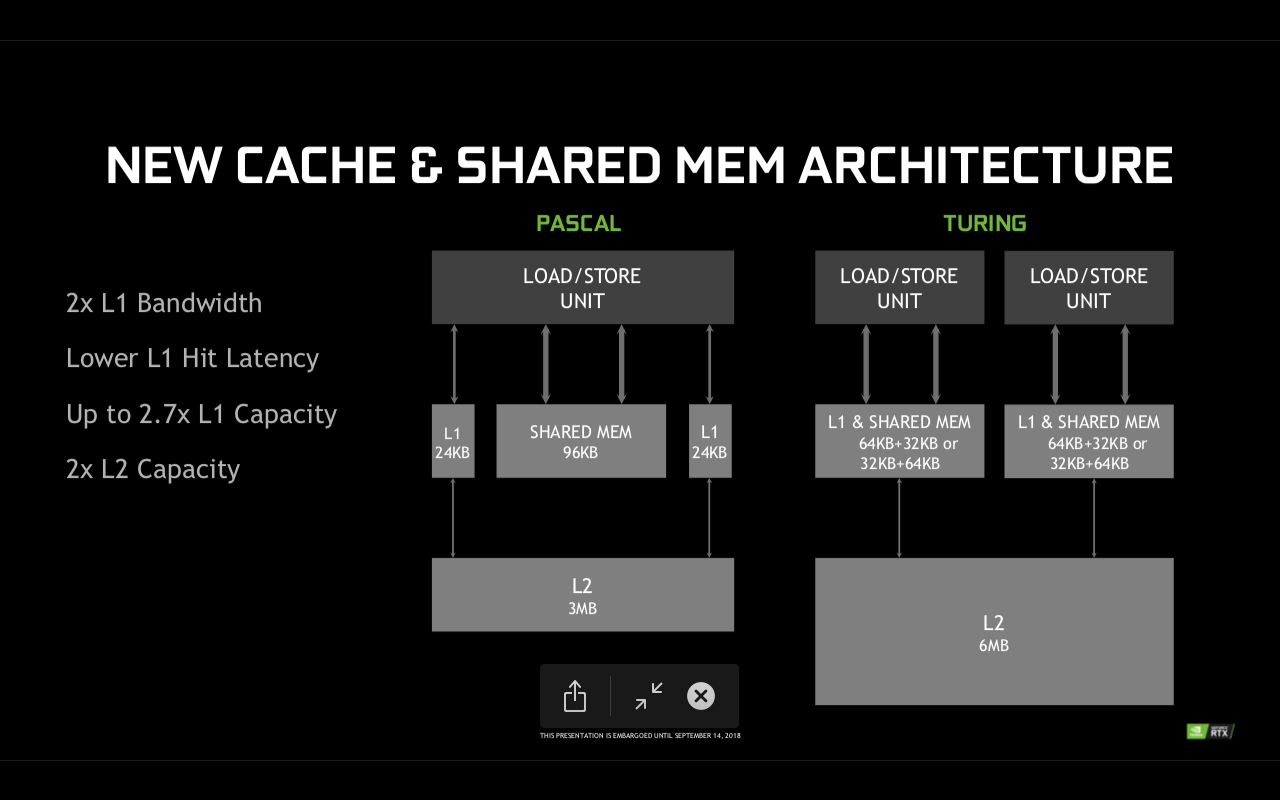
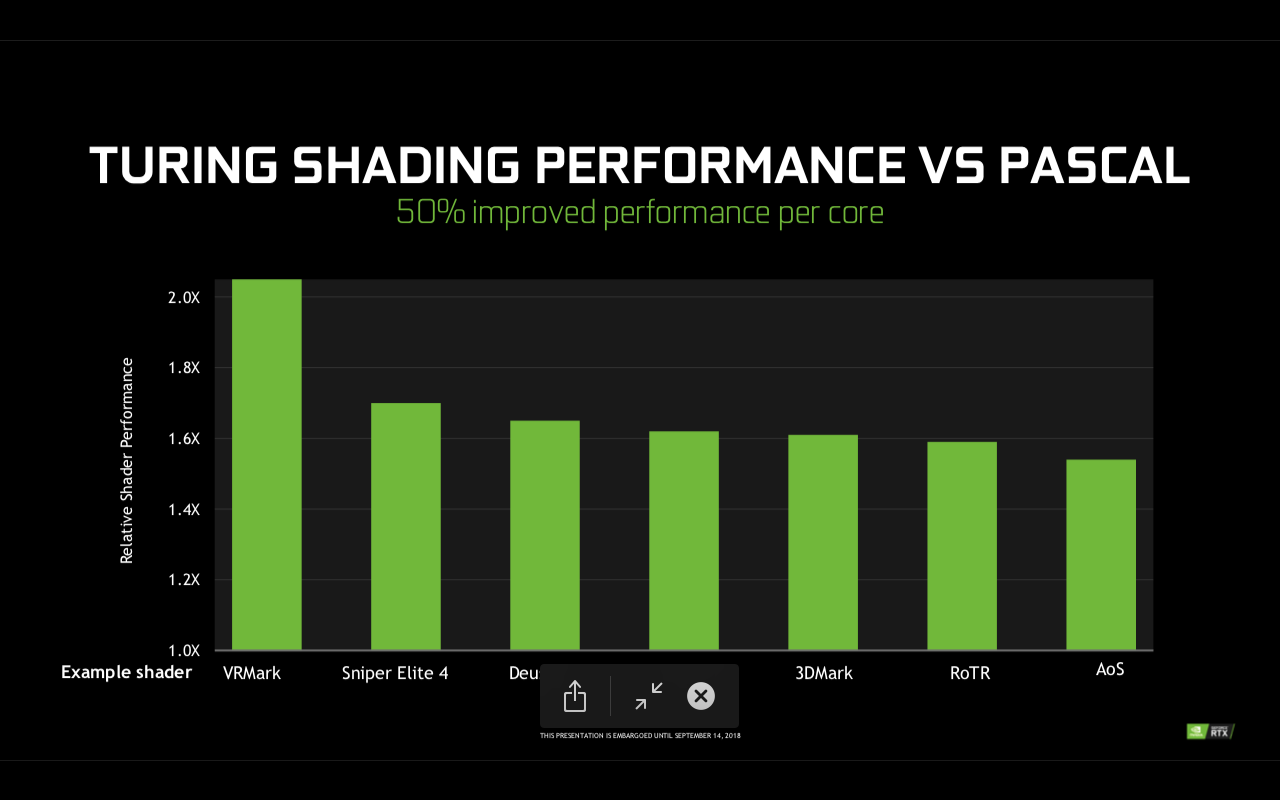
Restructurarea unitatilor de incarcare si stocare a adus o latime de banda dublata si capacitate marita de 2.7x pentru cache-ul L1, impreuna cu o dublare a cache-ului L2 de la 3MB la 6MB. Toate aceste imbunatatiri aduc o performanta per core cu pana la 50% mai mare daca este sa comparam Turing vs Pascal din acest punct de vedere.

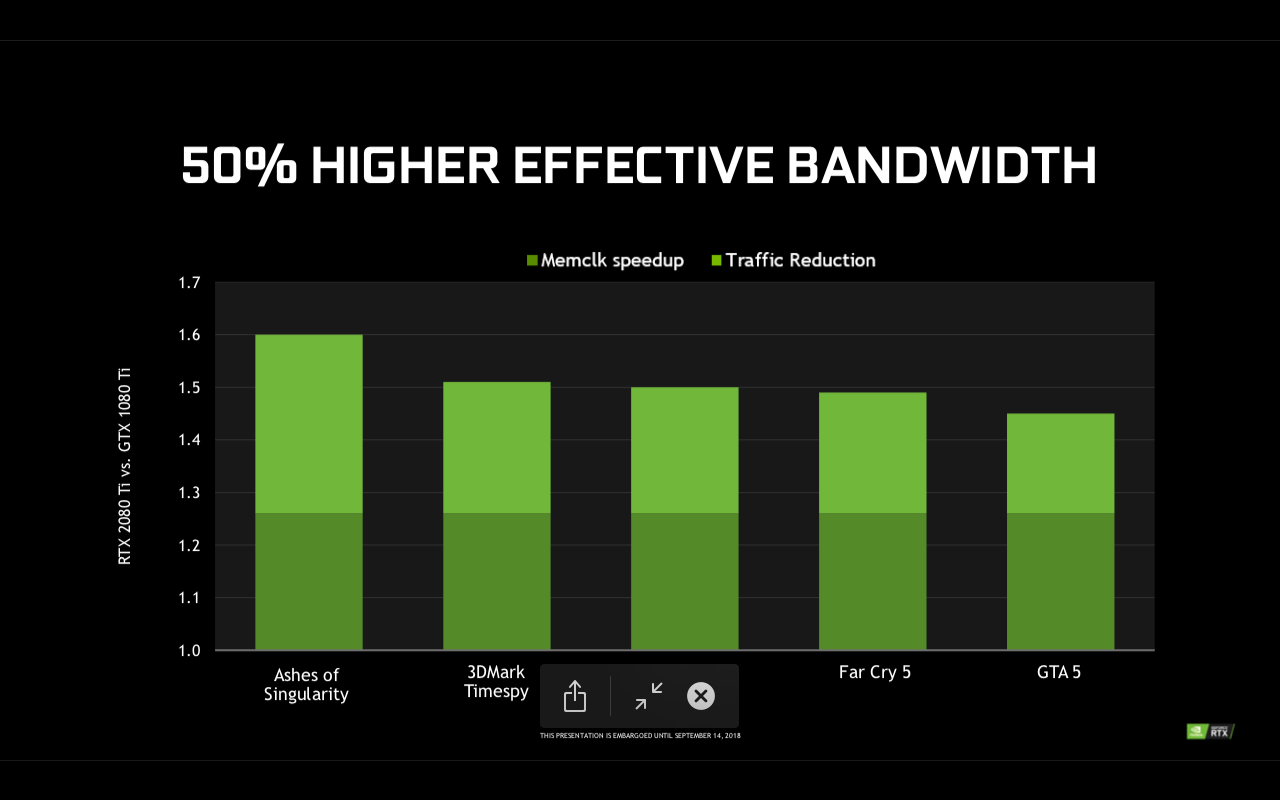
Cum o putere mai mare de procesare are nevoie de o latime mai mare de banda in ceea ce priveste memoria video, Geforce RTX este prima generatie de placi video echipata cu memorie GDDR6. Optimizarea procesului de fabricatie, precum si topologia imbunatatita, au permis ca GDDR6 sa aiba crosstalk mai mic cu 40% comparativ cu GDDR5. Asta inseamna ca avem parte de o viteza ridicata (14 Gbps) care impreuna cu reducerea traficului pe memorie face ca noile Geforce RTX sa vina la pachet cu un spor de 50% in ceea ce priveste latimea de banda.

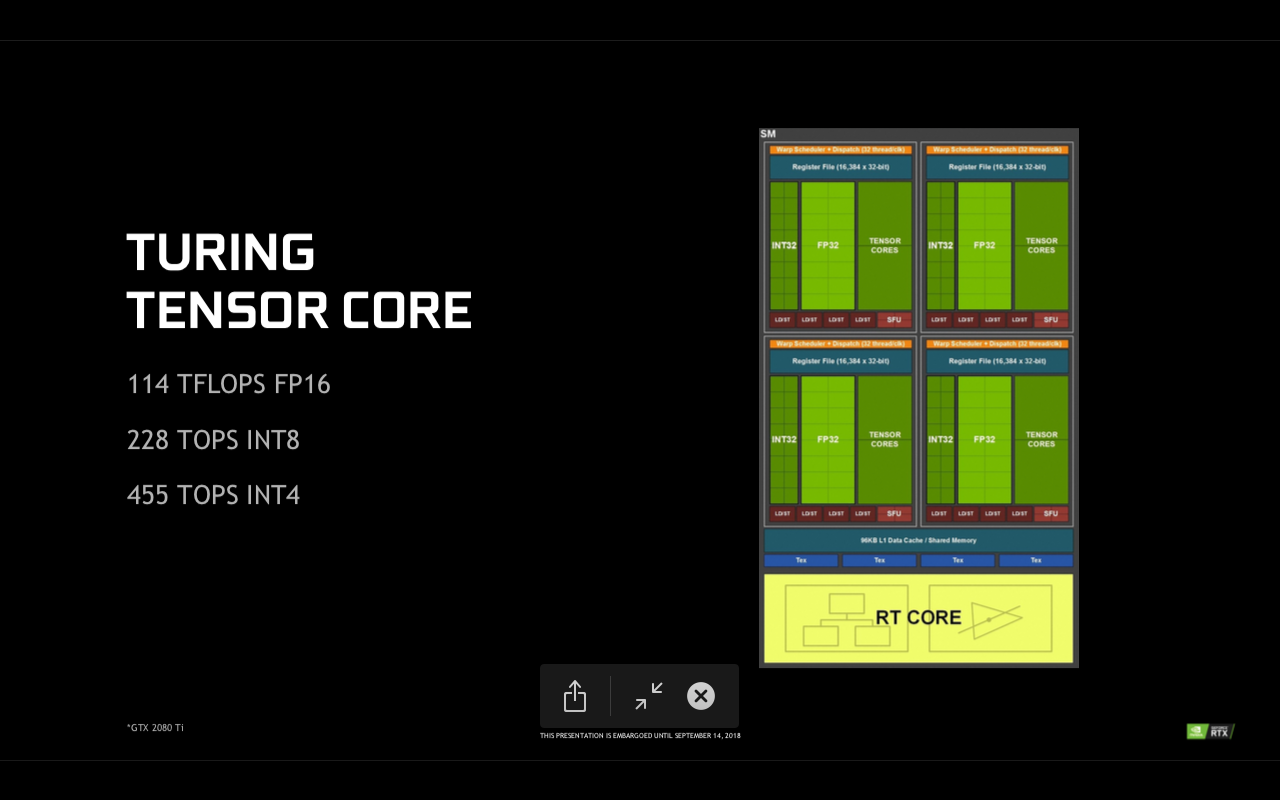
Asa cum va povesteam si in analiza arhitecturii Volta, nucleele Tensor, desi sunt mai putin flexibile din punct de vedere al programarii, sunt extrem de puternice in aplicatii de calcul HPC. Fata de GTX 1080, noile RTX 2080 sunt semnificativ mai rapide in procesare FP16 atunci cand nucleele Tensor sunt folosite, de regula in cazul retelelor neurale (training si interference). Avantajul simplitatii acestor nuclee este ca ocupa destul de putin spatiu pe pastila, iar NVIDIA au putut inghesui cate 8 pe fiecare SM (la fel ca la Volta). Totusi, nucleele Tensor sunt utile in special pentru algoritmi avansati de deep learning, prin urmare suportul software si optimizarea pentru ele trebuie realizate de catre dezvoltatori.
Intr-un fel lucrurile stau la fel si cu nucleele RT, cate unul prezent in fiecare SM al GPU-urilor Turing. Acestea servesc pentru randarea hibrida, unde imaginea finala este compusa atat din elemente rasterizate, cat si de elemente calculate prin ray tracing. Acest lucru sporeste viteza si produce imagine mai complexe, multi producatori de jocuri anuntand deja titluri importante care vor suporta aceasta tehnologie de randare hibrida.
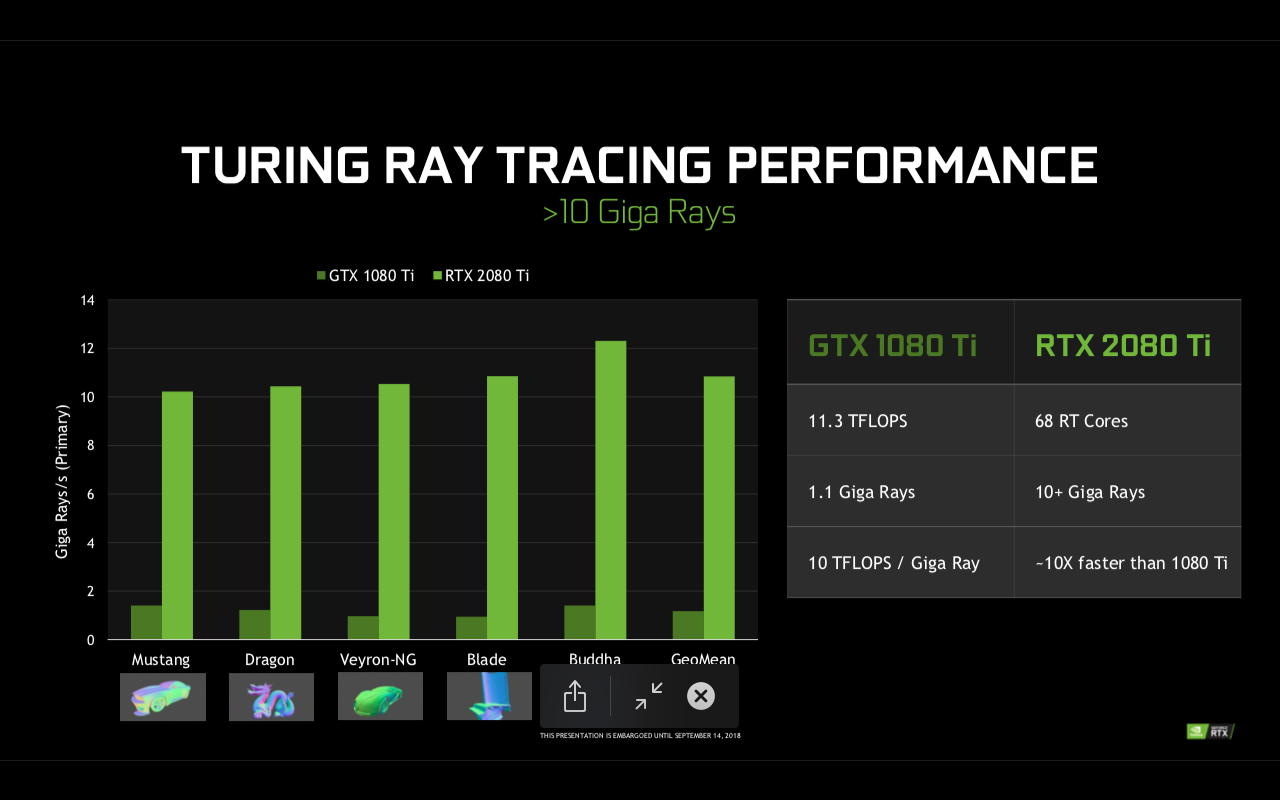
Pentru a intelege cat de importanta este prezenta nucleelor RT in GPU-urile Geforce RTX, trebuie sa intelegem cum se realizau pana acum operatiunile de ray tracing. In Pascal, de exemplu, aceastea erau executate de unitatile de shader, care trebuiau sa execute mii de instructiuni pentru a testa structura de BVH (Bounding Volume Hierarchy) pentru intersectii. Lesne de inteles faptul ca acest procedeu nu era deloc eficient, ray tracing-ul executat in lipsa unor unitati dedicate interferand si afectand performanta. In cazul lui Turing insa, unitatile RT se ocupa de traversarea BVH precum si de ray casting, ceea ce face ca unitatile SM sa se ocupe strict de operatiuni de vertex, pixel si compute. Intreg procesul devine mult mai eficient, sporuri importante de performante putand fi obtinute atunci cand jocurile vor suporta RTX.
Suportul RTX vine atat din partea hardware (nucleele RT prezente in arhitectura Turing), suport din drivere, cat si suportul software prezent in aplicatii (jocuri, etc). Aditia nucleelor RT si conceptul de randare hibrida este un eveniment suficient de important care sa justifice schimbarea denumirii din GTX in RTX. Daca procesoare Tensor am putut vedea atat in arhitectura Volta cat si in unele smartphone-uri, unitatile dedicate ray tracing (RT cores) sunt ceva cu adevarat nou si interesant.

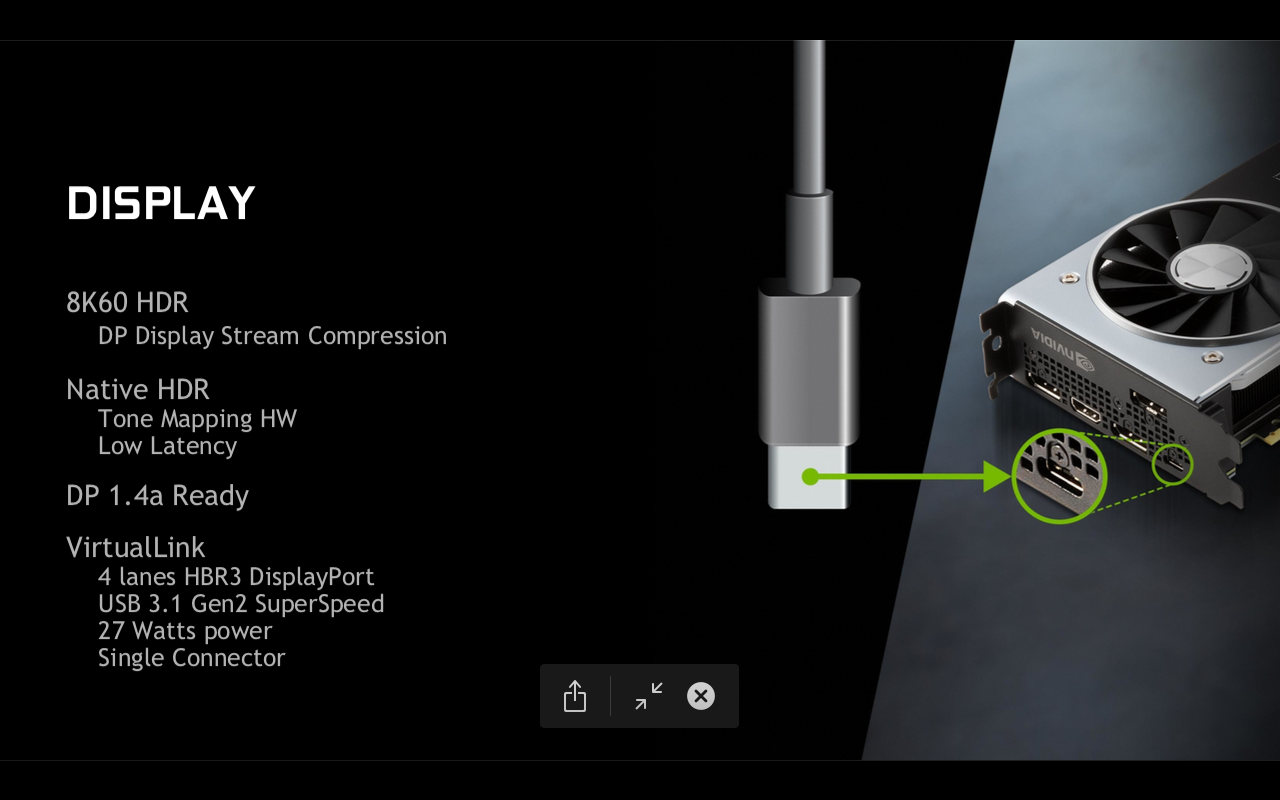

Placile Geforce RTX sunt pregatite pentru urmatorul val de headset-uri VR, prin urmare avem un port VirtualLink dedicat. Acesta combina conectivitatea HBR3 cu 4 lane-uri DP cu un port USB 3.1 ce poate sustine chiar si un consum de 27W.
Die-ul intreg aka “The big Kahuna” se numeste TU102 si vine cu 72 SM-uri active si 18.6 miliarde de transistori. 4608 procesoare CUDA, 576 Tensor Cores, 72 RT Cores, 36 unitati de geometrie, 288 unitati de texturare si 96 ROP-uri completeaza specificatiile acestui mamut. Memoria este de tip GDDR6, are o interfata pe 384biti si ruleaza la 7GHz.






Comentarii






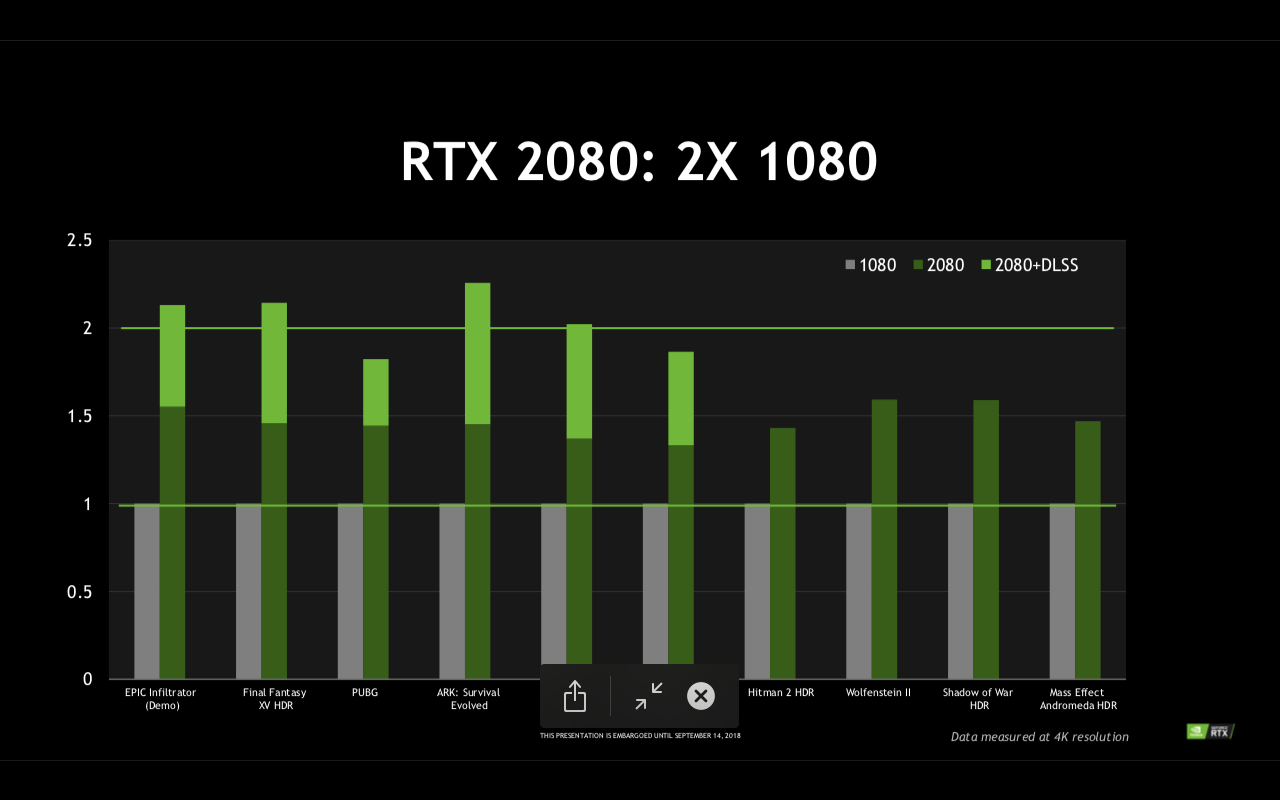
Salut! Mi se pare promițătoare DLSS. Cunoașteți mai multe detalii despre aceasta, de exemplu, cum funcționează?
Pingback: NVIDIA Geforce RTX 2080 & 2080 Ti – Part II – Arhitectura Turing | Stiri IT & C
Pingback: NVIDIA Geforce RTX 2080 & 2080 Ti – Part II – Arhitectura Turing - 1iT.ro - Stiri IT, noutati si tehnologie