Inteligenta Artificiala pe PC-ul tau – RTX la maturitate – Part VI

AI generativ – Stable Diffusion
Ati vazut toate site-urile si aplicatiile cu ajutorul carora puteti genera imagini online, folosind serverele companiei? Este interesant sa poti sa generezi aproape orice imagine iti doresti, aplicatiile fiind nelimitate, in special intr-un mediu creativ. De exemplu, probabil ati observat ca in proportie de 99% noi utilizam pe site doar imagini realizate de noi, indiferent daca discutam despre screenshot-uri sau fotografii cu produse. Ei bine, ce imagini am fi putut utiliza in articolul de fata (cu exceptia celor doua pagini de screenshot-uri)? Imagini generate local, cu ajutorul inteligentei artificiale!
Da, atat thumbnail-ul, cat si imaginile de pe primele 3 pagini, respectiv ultima pagina, au fost generate cu ajutorul unui model AI. Spre deosebire insa de site-urile care fac asta, noi am facut-o gratuit, local, pe PC-ul nostru de teste. Pentru asta am folosit modelul text-to image denumit Stable Diffusion. Acesta a fost lansat in 2022 si este bazat pe algoritmi de Deep Learning, fiind antrenat pe un data-set care contine 5 miliarde de perechi text-imagine culese de pe internet. Intre timp, Stable Diffusion a trecut prin 7 versiuni, capatand si capabilitati de modificari ale imaginilor (image to image), respectiv integrari cu alte seturi de date.
Compania care produce acest model, Stability AI, ofera doua interfete proprietare, DreamStudio si StableStudio, insa noi am folosit o interfata Open Source gratuita, mai precis AUTOMATIC1111 Stable Diffusion Web UI. Mai mult decat atat, pentru a folosi la maxim puterea de procesare oferita de placa noastra video, am folosit extensia TensorRT. Ei bine, asa cum spuneam, nu suntem experti in solutii AI, drept urmare am urmat pas cu pas tutorialul pus la dispozitie de catre cei de la Nvidia, apoi am instalat cateva modele in plus. Daca vreti sa experimentati cu AUTOMATIC1111 Stable Diffusion Web UI si TensorRT, va sfatuiesc sa urmati acelasi tutorial.
Instalarea si configurarea modelului AI dureaza intre 30 de minute si o ora, in functie de performanta sistemului vostru, respectiv performanta conexiunii la internet. Daca intampinati probleme in timpul instalarii, in special mesaje legate de DLL-uri lipsa, va recomand sa instalati Visual Studio, Python 3.12, ultima versiune de Microsoft Visual C++ Redistributable si Nvidia CUDA Toolkit. La final, daca ati urmat tutorialul, ar trebui sa aveti in fata interfata web de mai jos.
Aici avem acces la mai multi parametri, cum ar fi modelul AI, checkpoint-ul pentru care acesta a fost antrenat pe PC-ul nostru, prompt-ul pozitiv (unde scriem efectiv ce vrem sa generam), prompt-ul negativ (unde listam conditiile pe care le dorim excluse), precum si parametri tehnici, cum ar fi motorul de sampling, numarul de pasi, rezolutia imaginii finale s.a.m.d. Desigur, daca vreti sa aprofundati subiectul, exista nenumarate ghiduri si tutoriale pe internet, care explica fiecare setare in parte.
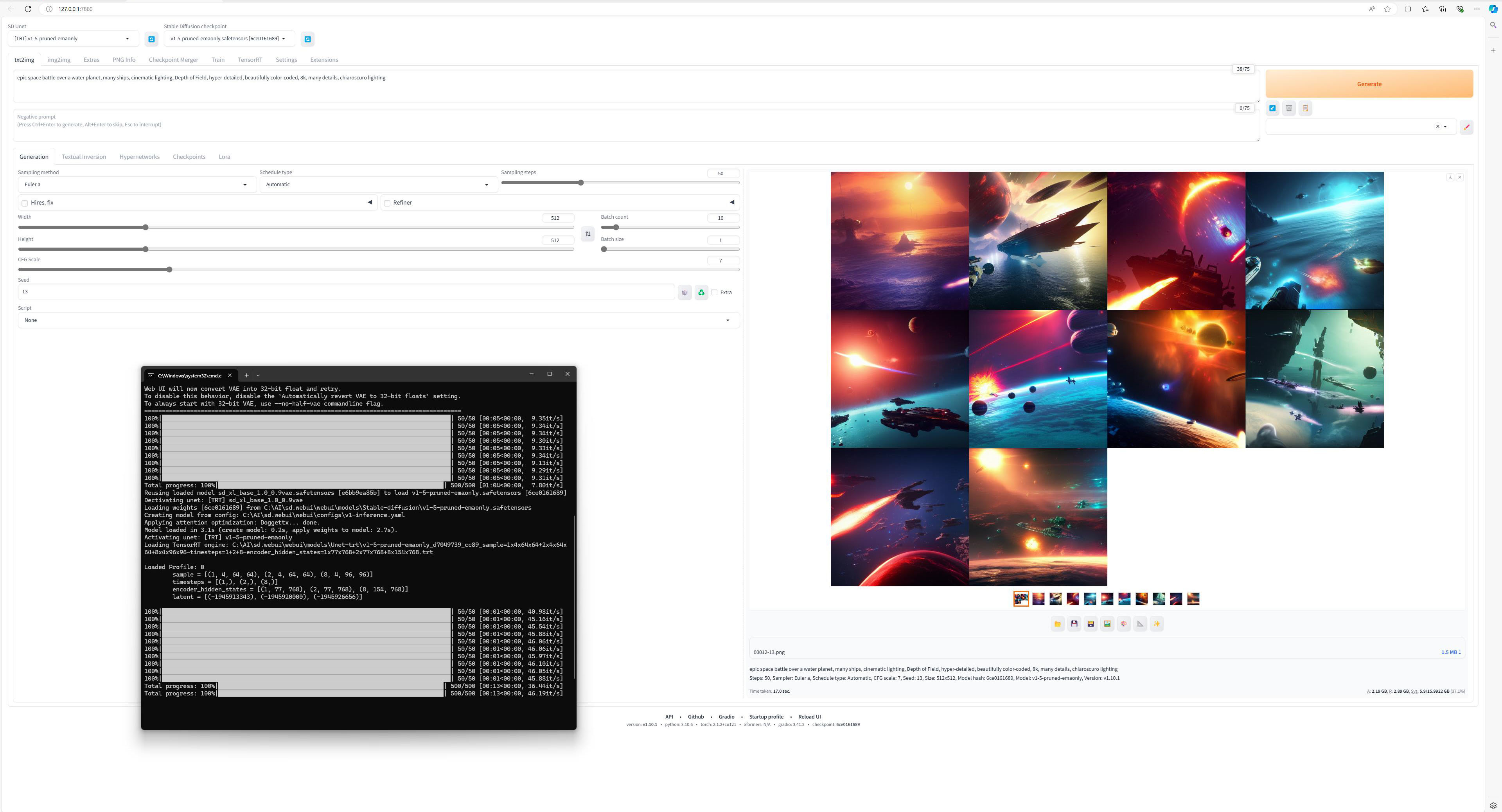
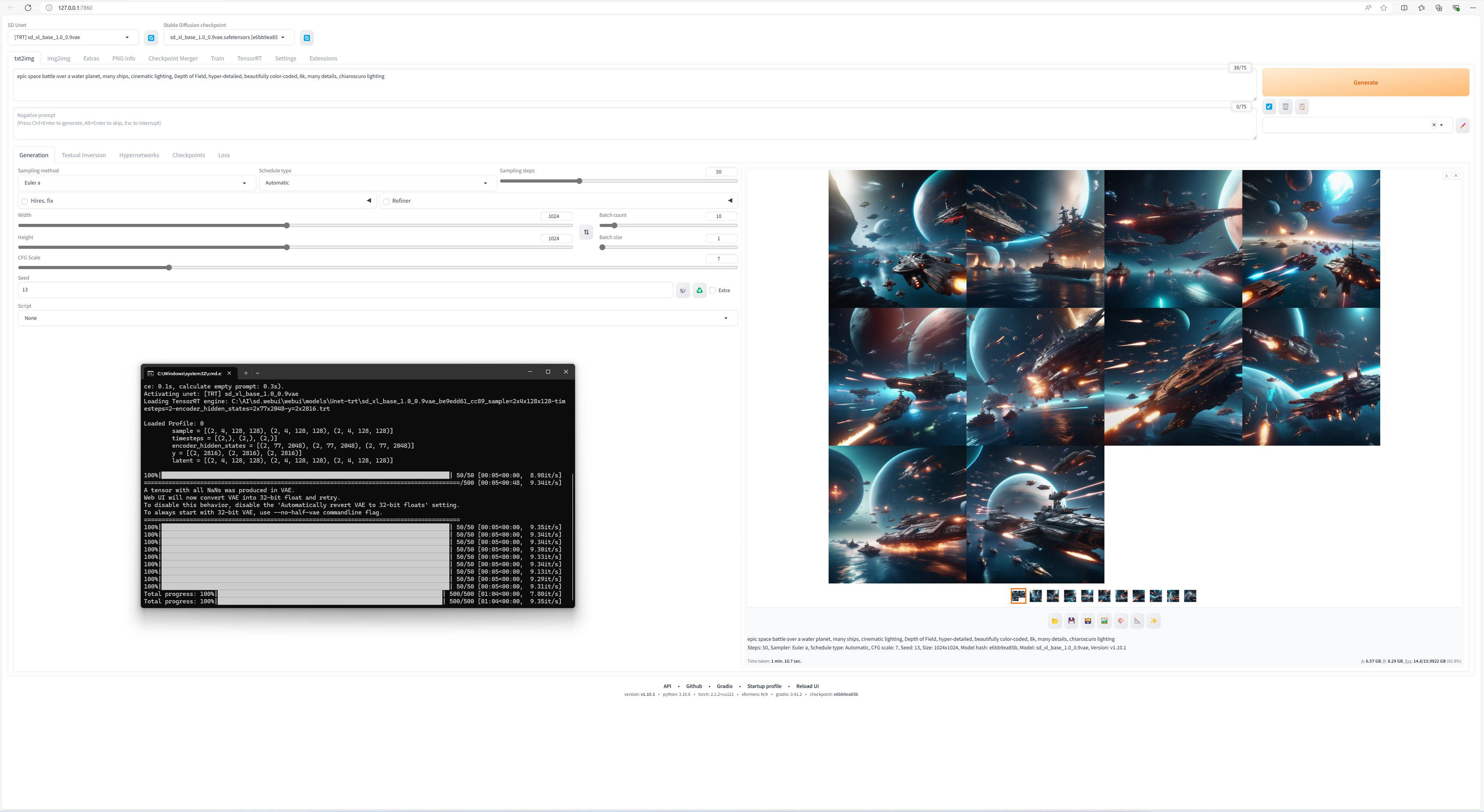
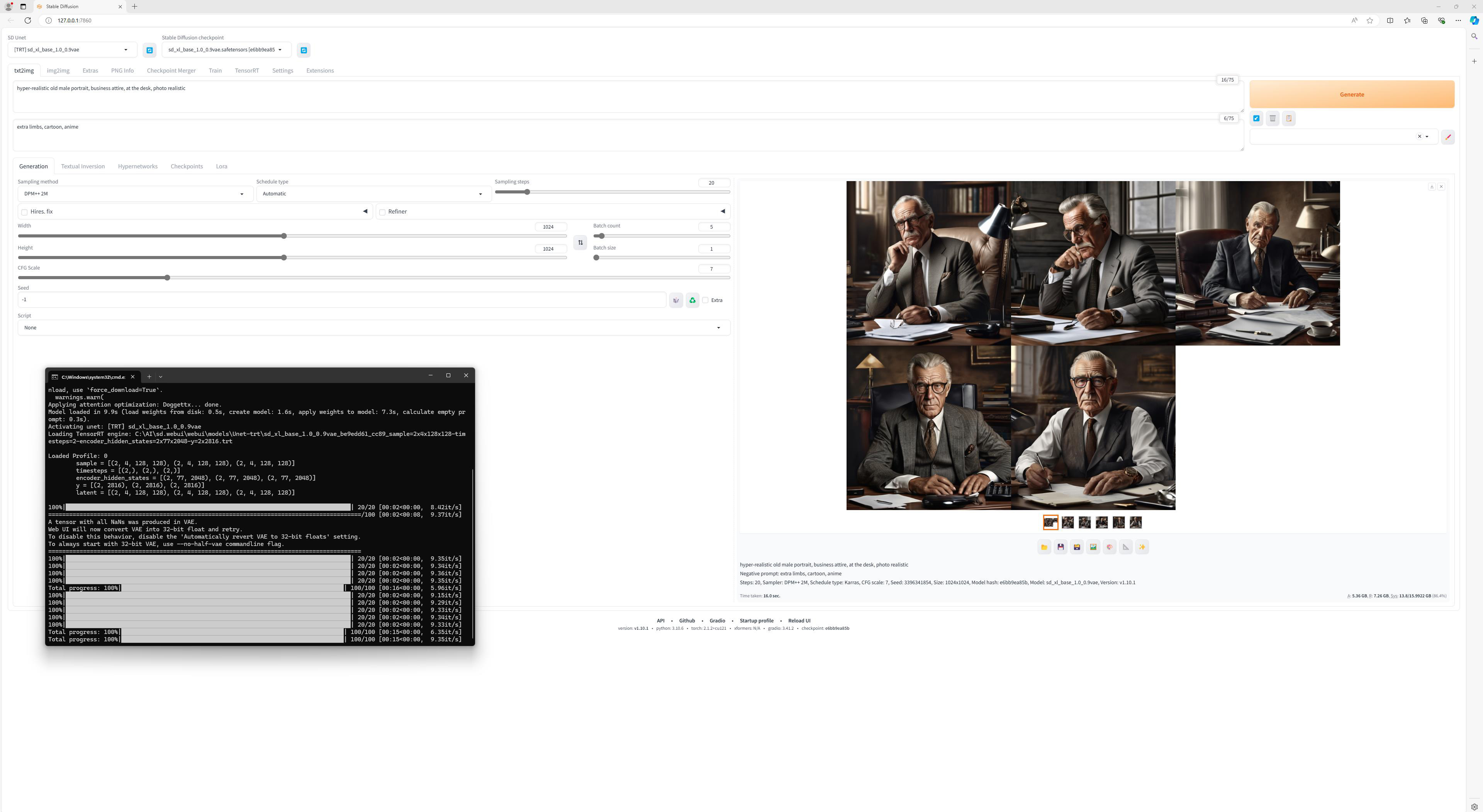
Noi am folosit mai intai Stable Diffusion SDv1.5 checkpoint, pentru a genera imagini 512×512, cu prompt-ul “epic space battle over a water planet, many ships, cinematic lighting, Depth of Field, hyper-detailed, beautifully color-coded, 8k, many details, chiaroscuro lighting”. Apoi am trecut la Stable Diffusion SDXL si am repetat scena, de aceasta data pentru o rezolutie de 1024×1024.
In ambele cazuri setarile au fost:
Sampling Method: Euler a
Sampling Steps: 50 (ulterior am folosit 20, pentru o mai buna stabilitate)
CFG Scale: 7
Batch Size: 1
Batch Count: 10 (ulterior am folosit 5)
Seed: 13
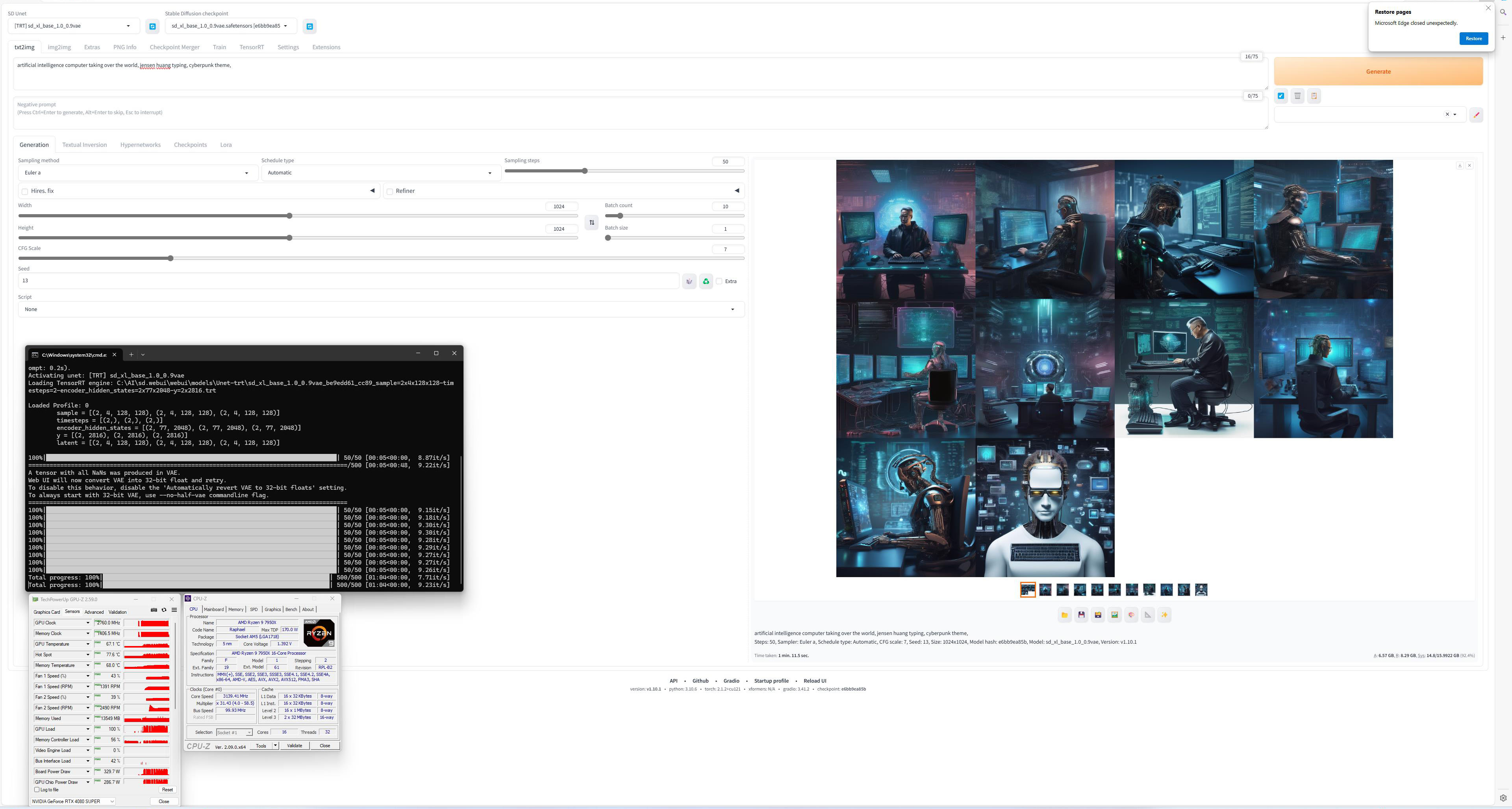
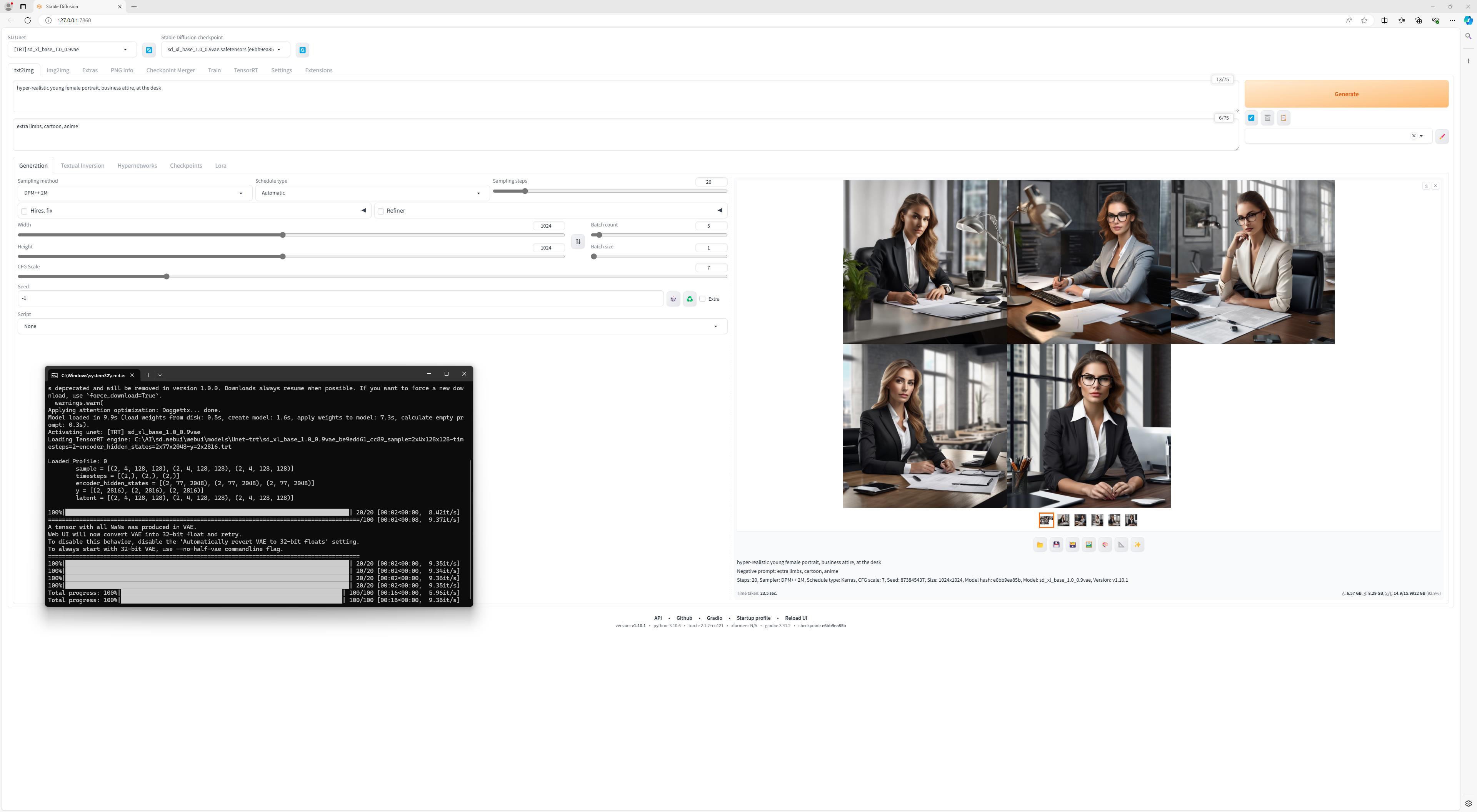
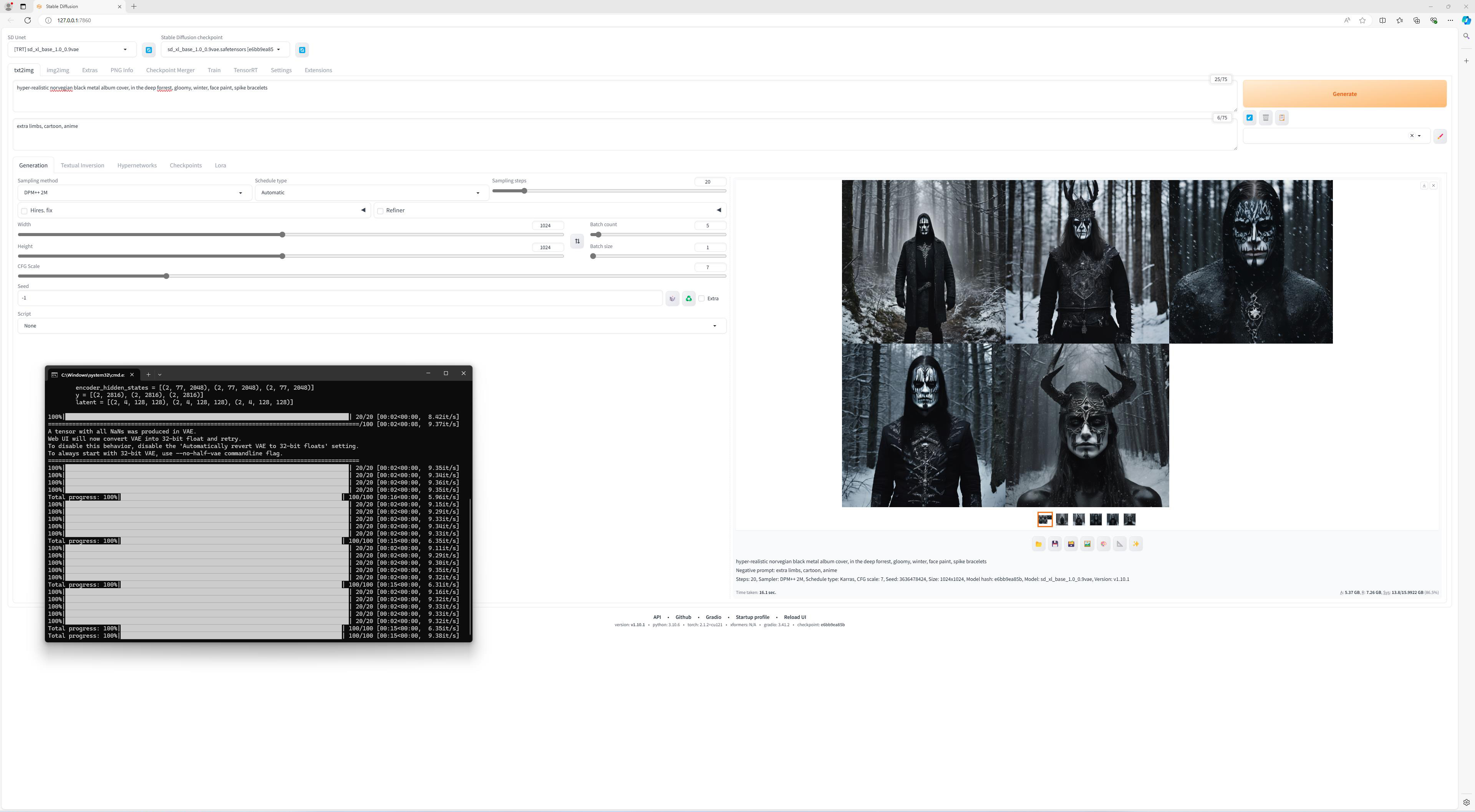
Ulterior, pastrand setarile de mai sus am generat mai multe tipuri de imagini, pentru a vedea de ce este capabil Stable Diffusion. Desigur, fiind vorba despre un motor public, exista limitari impuse din start, legate de utilizarea imaginii unei persoane publice, pentru a elimina riscul deepfake-urilor, nuditate, violenta, s.a.m.d. Exista desigur si modele si checkpoint-uri mai putin cenzurate, care pot fi utilizate cu aceeasi interfata, la fel cum exista modele specializate pe anumite subiecte.
Cert este ca daca nu vreti sa generati imagini cu figurile unor persoane publice, nuditate excesiva sau nume de brand-uri sau locuri, modelul standard se descurca in general destul de bine. Chiar si asa, asta nu inseamna insa ca totul este perfect, modelele utilizate de noi avand o predilectie pentru a nu reprezenta exact cum trebuie degetele sau numarul lor, in anumite imagini.
Desigur, eu am dat mai sus doar un exemplu simplu de image to text, in realitate insa posibilitatile sunt nelimitate, Stable Diffusion permitandu-ne sa modificam imagini sau sa generam imagini pe baza altor imagini. Practic, aproape orice este posibil, atata timp cat depunem un minim de efort pentru documentatie si alocam 2-3 ore pentru experimentare. Si mai important, asa cum am mai spus-o, totul se intampla gratuit, local, in singuranta, pe PC-ul tau echipat cu o placa grafica NVIDIA RTX.
Partea buna este ca odata instalat si antrenat modelul de AI, generarea imaginilor devine o joaca cu ajutorul placii grefice, NVIDIA GeForce RTX 4080 SUPER putand genera aproximativ 45 de imagini 512×512 pe minut, sau 9 imagini 1024×1024 pe minut, o performanta net superioara fata de orice procesor sau placa grafica de la alt producator.

















































































Comentarii